Overview over NASA's new RISC-V-based Processor

It happens not often that NASA switches to a new processor for their spacecraft. For example the rover Perseverance, which landed on Mars in 2021, uses for its processor the RAD750, developed some 30 years ago. Its based on a PowerPC 750, the one that was also used in the original iMac. Since then the hardware and software have proven themselves on many missions. However its compute performance, scalability, security and fault tolerance are lacking. In 2022 NASA awarded Microchip with a contract to design a new processor. Its to be used an all future lunar and planetary missions. The new processor should provide 100x the compute performance and also address the other needs. Recently Microchip announced that this processor is now being delivered. Its called PIC64-HPSC.
The main function blocks are depicted in the block diagram below:
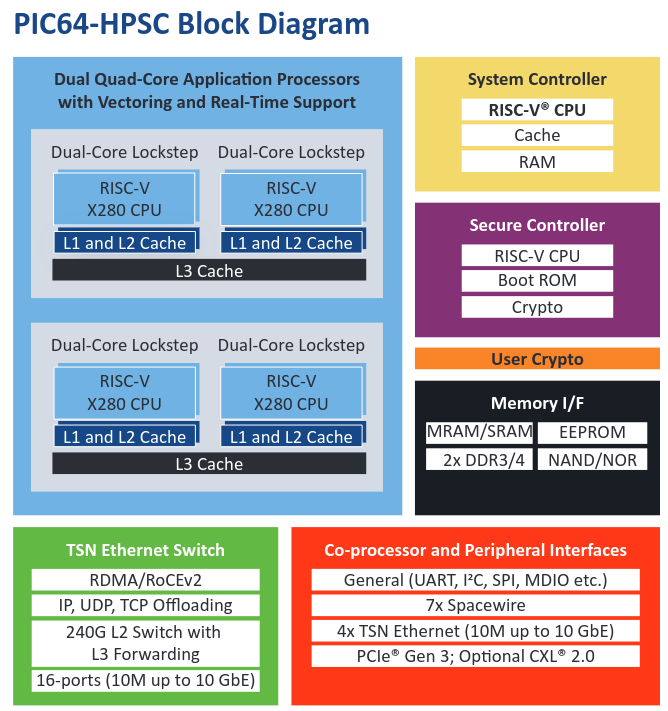
It looks like a modern processor containing next to the CPU, memory and system controller a dedicated security coprocessor, lots of peripherals and an Ethernet Switch.
Processing Performance and Fault tolerance
The processing power is delivered by 8 SiFive X280 CPU Cores. The X280 is advertised with a compute performance of 4.6 Specint2k6 / GHz.
I'v tried to find ARM Cores with a similar Specint2k6 score. The closest one I found was a Cortex A75, estimated at 6.8 / Specint2k GHz.
Going by ARMs advertised generational performance gains of 20 % (A75 over A73) and 30 % (A73 over A72) and doing some crude math this would put the Cortex A72 at a similar performance level:
6.8 / (1.3 * 1.2) = 4.3 Specint2k6 / GHz
compared to SiFives X280. The Cortex A72 is used for example in the Raspberry Pi 4's Broadcom BCM2711 SoC. Given its similar performance and power level and popularity I thought the Pi 4 to be an interesting comparison point. Additionally its meant to highlight some space specific particularities of the PIC64, as the Pi is not build for space application but meant for teaching and sees some industrial applications.
The following table compares key specs of the Microchip PIC64 HPSC1000 with its predecessor the BAE RAD750 and the Raspberry Pi 4 SoC BCM2711.
| BAE RAD750 | Microchip PIC64 HPSC1000-RH | Raspberry Pi 4 Broadcom 2711 | |
|---|---|---|---|
| 1x RAD750 | 8x SiFive X280 | 4x ARM Cortex A72 | |
| ISA | PowerPC | RISC-V | ARM |
| fmax |
200 MHz | 1000 MHz | 1500 MHz / 1800 MHz |
| MIPS | 366 | 26000 | |
| Real Adress Range | 32 bit | 64 bit | 64 bit |
| Cache L1 | 32 KiB I$ 8-ways 32 KiB D$ 8-ways |
32 KiB I$ 4-ways 32 KiB D$ 4-ways |
48 KiB I$ 3-ways 32 KiB D$ 2-ways |
| Cache L2 | external | shared 2 MiB | shared 1 MiB 16-ways |
| Execution Sequence | Out of Order | in order | Out of Order |
| Pipeline Stages | 4 | 8 | 15 |
| Issue Width | 2 | 2 (Scalar) + 1 (Vector) | 8 (Scalar/Vector) |
| Vector Length | n.a. | 512 bit (512 bit datapath) | 128 bit (64 bit data path) |
| Memory | SDRAM 256 MB ECC 133 MT/s * 64 bit = 1 GB/s |
DDR3-2133 or DD4-3200 max 2x32 GB with multi-Bit ECC 3200 MT/s * 128 bit = 51.2 GB/s |
LPDDR4-3200 max. 8 GB 12.8 GB/s |
Compared to recent x86 or ARM application class processors found in Laptops or Smartphones, SiFives X280 cores scalar processing capabilities are limited. Up to two instructions can be issued per cycle which are executed in order. In comparison even the Cortex A72 of the Raspi 4 are much more complex: capable of changing the instruction sequence to utilize the eight functional units as best as possible. What sets the X280 apart from many other core designs with similar scalar capabilities is the 512 bit long vectors with a true 512 bit data path. In comparison the Cortex A72 has smaller 128 bit vectors while the internal data path is only 64 bit. This means when using vector instructions, the per cycle throughput of an X280 core is 8 times higher compared to an Cortex A72. When using small numbers like INT8, which are typical for machine learning, up to 64 Multiply-Accumulate (MAC) operations can be performed by one 512-bit vector instruction.
On x86 512 bit vectors are part of the AVX512 instruction set extension. This can be found only in recent high performance µArch like Zen4/Zen5 and some Intel CPUs. Looking in the ARM world, 512 bit vectors are possible via the Scalable Vector Extensions (SVE). 512 bit vectors are used e.g. in Fugaku, worlds fastest supercomputer from 2020 to 2022 or Amazons data center processor Graviton3.
These vector processing capabilities allow the processor, which does not feature a dedicated Neural Processing Unit, to provide some reasonable throughput at advertised 2 TOPS. The TOPS number represents the theoretical maximum number of 8-bit-integer Multiply-Accumulate (MAC) operations that can be performed per second by all cores. A "G" refers to 10⁹ (Giga) or one billion, a "T" refers to 10¹² (Tera) or a trillion.
The OPS are the product of the number of cores, the frequency f and the number of 8 bit operations per vector. Although Multiply-Accumulate (MAC) is typically executed using just one instruction, its counted as two operations, hence the factor 2.
For comparison the latest iPhone 15 Pro features a dedicated NPU, capable of 35 TOPS, while Microsoft requires at least 40 TOPS for their "AI PCs".
The following table compares the performance of NASAs old and new processor as well as the P i4, using some popular CPU benchmarks where I could scores. Higher is better. Overall the performance uplift is substantial, achieving 65x the DMIPS score of previous processor. Compared to the ARM Cortex A72 cores in the Pi, the single core is worse, maybe half as good. The multicore performance seems on a similar level, thanks to having double the amount of cores.
| System | BAE RAD750 | Microchip PIC64 HPSC1000-RH | Raspberry Pi 4 |
|---|---|---|---|
| Single Core | 1x RAD750 @ 200 MHz | 1x SiFive X280 @ 1000 MHz | 1x ARM Cortex A72 @ 1500 MHz |
| Dhrystone MIPS | 400 | 3250* | 8176 |
| Dhrystone MIPS / MHz | 2* | 3.25 | 5.45 |
| specINT2k6 / GHz | 4.6 | 4.3* | |
| All Core | 8x SiFive X280 @ 1 GHz | 4x ARM Cortex A72 @ 1800 MHz | |
| DMIPS | 400 | 26,000 | |
| CoreMark | 46,000 | 48,628 | |
| INT8 own calc | 1 * 0.2 GHz * 2 = 0.4 GOPS | 8 * 512/8 * 1 GHz *2 = 1000 GOPS | 4 * 64/8 * 1.5 GHz *2 = 96 GOPS |
| INT advertised | 2000 GOPS |
*indicates own calculations based on reported scores
The CPU can be configured to run in lockstep, trading off half the CPU cores for increased fault tolerance, e.g. detection of single event upsets. With lockstep, a pair of CPUs executes the same code, with some cycles delay between them. When ever they come to different results, an error is raised and appropriate action can be taken. This can be as simple as running the code section again.
Next to the eight main CPU cores, there are two RISC-V cores embedded into the system and secure controller. Those are meant for house keeping tasks, freeing up the main CPU. This underscores the flexibility of the RISC-V architecture, being able to scale from simple embedded class cores to complex application class cores.
The secure controller acts as a platform root of trust. It supports secure boot. Additionally the post quantum cryptography protocols ML-KEM and ML-DSA are supported.
Scalability and Flexibility
Notable peripherals are CXL (Compute Express Link) TSN (Time Sensitive Networking). Those are relatively new standards, released only in the 2010s and 2020s, compared to I2C and SPI, released in the 1980s.
CXL was originally developed for high performance data center computers. It allows the host CPU and devices to work together in a shared coherent memory space. The coherency is managed by the CPU, enabling low latency and efficient memory access with a less compex software stack. Processing workloads can be more easily distributed between the CPU and accelerators (e.g. FPGA, GPU). This allows NASA to flexibly scale the performance of the computer as required by future missions.
TSN makes Ethernet based networks real-time capable. In contrast to Ethernet, there needs to be a guarantee that messages can be received within a certain maximum delay. This is important e.g. in control tasks like landing a spaceship where motors have to react to sensor input within a certain time frame, otherwise the spaceship will crash.
| Processor | BAE RAD750 | Microchip PIC64 HPSC1000-RH | Raspberry Pi 4 BCM2711 |
|---|---|---|---|
| Cores | 1x RAD750 | 8x SiFive X280 | 4x ARM Cortex A72 |
| Temperature | - 55 °C to 125 °C | -55 °C to 125 °C | 0 °C to 50 °C |
| Total Ionizing Dose | 1000 krad | 200 krad | |
| Technology | 250 nm | 28 nm | |
| Power | 10 W | ~ 5 W | |
| MIPS | 366 | 26000 | |
| Peripherals | UART PCI |
UART, I2C, SPI 4x TSN Ethernet 10 Mb up to 10 Gb PCIe Gen 3x8 + CXL 2.0 |
UART, I2C, SPI Ethernet 1 Gb USB |
| Production Lifetime | January 2034 |
References
NASA Contract Announcement https://www.nasa.gov/news-release/nasa-awards-next-generation-spaceflight-computing-processor-contract/
Microchip PIC64 HPSC Announcement https://www.microchip.com/en-us/about/news-releases/products/microchip-unveils-industrys-highest-performance-64-bit-hpsc-mpu
SiFive X280 Specsheet https://sifive.cdn.prismic.io/sifive/9405d3d0-35a1-4680-a259-7a5598d1ecb2_sifive-intelligence-x200-datasheet.pdf
BAE RAD750 https://www.baesystems.com/en-media/uploadFile/20210404045936/1434555668211.pdf
http://powerpc.i-logout.cz/docs/rad750.pdf
Microchip PIC64 HPSC Series Specsheet https://ww1.microchip.com/downloads/aemDocuments/documents/MPU64/ProductDocuments/Brochures/PIC64-HPSC-Series-00005391.pdf