Analyzing the STREAM Benchmark
The Stream benchmark is designed to measure sustainable memory bandwidth and computation rate for simple vector kernels.
What the benchmark does
The stream benchmark runs four kernels above arrays of 10 million FP64 elements. Bandwidth is calculated as the time from loading the first element until storing the last element of each kernel. The best bandwidth achieved is reported.
The kernels are called copy, scale, sum and triad and perform the following operations:
Copy Kernel
The copy kernel (Line 315) performs the operation c[j] = a[j]. It performs no arithmetic but involves the movement of 16 Byte of data, 8 Byte load and 8 Byte store.
Scale Kernel
The scale kernel (Line 325) performs the operation b[j] = scalar * c[j]. It consists of one arithmetic floating point operation per 24 Byte movement of data. 16 Byte are loaded, 8 Byte are stored.
Sum Kernel
The Sum kernel (Line 335) performs the operation c[j] = a[j] + b[j]. It consists of one arithmetic operations per 24 Byte of moved data. 16 Byte are loaded, 8 Byte are stored.
Triad Kernel
The triad kernel (Line 345) performs the operation a[j] = b[j] + scalar * c[j]. It consists of two arithmetic operations per 32 Byte of moved data. 24 Byte are loaded, 8 Byte are stored.
These kernels share two characteristics of low arithmetic intensity and spatial locality. They allow prefetchers to maximize the data rate when loading data from memory into the caches.
The data set is chosen large enough to not fit inside the last level cache. Each arrays is 8 Byte/element * 10e6 elements = 80 MB. They exceed typical L3 Cache sizes of 32 MB (Ryzen 7000).
Each kernel is run 10 times to remove noise, resulting in each kernel operation being run a total of 100 million (10e8) times.
What the CPU executes
I compiled the stream source with gcc and the recommended first optimization level with the following command:
gcc -O -o stream stream.c
To analyze the used instructions I ran the binary with Intels Software Development Emulator in version 9.33 with the following command:
sde -rpl -mix -- stream
STREAM uses 127 different instructions. The top ten instructions account for almost 99 % of all 2.7 billion instructions executed. They are the following:
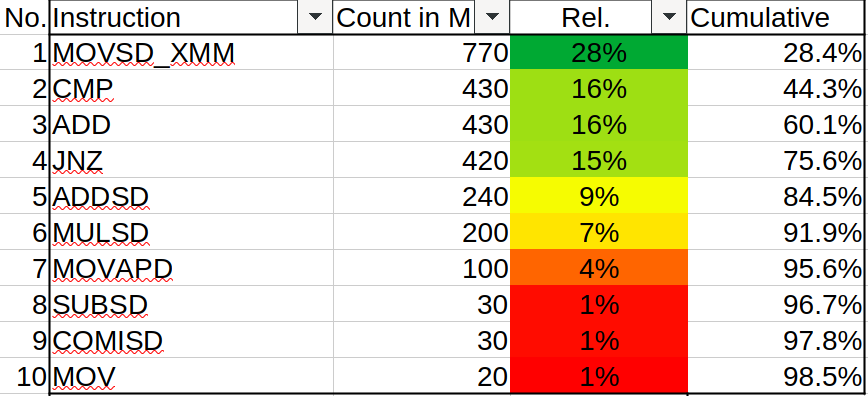
The top 7 instructions belong to the kernels used to measure the memory bandwidth. They account 96 % of all instructions. The most used instruction is MOVSD_XMM which is used both to load data from memory into a register and to store data from a register into memory. Even though STREAM is described as measuring bandwidth by executing vector kernels, with the recommend optimization level -O gcc doesn't use any vector instructions. Even though MOVSD, ADDSD, MULSD and MOVAPD utilize xmm vector register, they only operate on scalar values.
To better understand how these instructions are used, I created a listing file and analyzed the assembly of the kernels.
I created the listing file using the same optimization level -O and inserted debug symbols. The full command looks the following:
gcc -g -O -Wa,-adhln -masm=intel stream.c > stream.lst
Assembly of Copy Kernel (Line 315): c[j] = a[j]
Below is the assembly of copy kernel generated from the source code c[j] = a[j].
movsd xmm0, QWORD PTR [r12+rax*8] ; load a into xmm0
movsd QWORD PTR [rbx+rax*8], xmm0 ; store xmm0 where c points at
add rax, 1 ; j++
cmp rax, 10000000 ; set status flags depending on j == 10e6
jne .L85 ; if j != 10e6 jump to the beginning of the copy kernel
Assembly of Scale Kernel (Line 325): b[j] = scalar * c[j]
Below is the assembly of scale kernel generated from the source code b[j] = scalar * c[j].
movsd xmm0, QWORD PTR .LC4[rip] ; load scalar value into xmm0
mulsd xmm0, QWORD PTR [rbx+rax*8] ; xmm0 = scalar * c[j]
movsd QWORD PTR 0[rbp+rax*8], xmm0 ; store scalar * c[j]
add rax, 1 ; j++
cmp rax, 10000000 ; set status flags depending on j == 10e6
jne .L86 ; if j != 10e6 jump to the beginning of the scale kernel
Note how the scalar is loaded at each iteration from memory, even though it is a constant value. This is necessary because the next instruction mulsd writes its result in the same register from where it read the first operand. This is a limitation of the instruction that supports only two operands. Its unclear to me why gcc did not allocated a different register like xmm1 or chose the vmulsd which would have allowed a third operand for the destination register. ARM and RISC-V instructions have three operands, and thus allow the destination register to be different from the source registers.
Assembly of Sum Kernel (Line 335): c[j] = a[j] + b[j]
Below is the assembly of the Sum Kernel generated from the source code c[j] = a[j] + b[j].
movsd xmm0, QWORD PTR [r12+rax*8] ; load a[j] into xmm0
addsd xmm0, QWORD PTR 0[rbp+rax*8] ; c[j] = a[j] + b[j] (reg xmm0 used to load operand and to store result)
movsd QWORD PTR [rbx+rax*8], xmm0 ; store c[j]
add rax, 1 ; j++
cmp rax, 10000000 ; set status flags depending on j == 10e6
jne .L87 ; if j != 10e6 jump to the beginning of the sum kernel
Assembly of Triad Kernel (Line 345): a[j] = b[j] + scalar * c[j]
Below is the assembly of Triad Kernel generated from the source code a[j] = b[j] + scalar * c[j].
movapd xmm0, xmm1 ; move scalar into xmm0, (just before the loop, scalar was loaded into xmm1)
mulsd xmm0, QWORD PTR [rbx+rax*8] ; xmm0 = scalar * c[j]
addsd xmm0, QWORD PTR 0[rbp+rax*8] ; xmm0 = b[j] + scalar * c[j]
movsd QWORD PTR [r12+rax*8], xmm0 ; a[j] = xmm0
add rax, 1 ; j++
cmp rax, 10000000 ; set status flags depending on j == 10e6
jne .L88 ; if j != 10e6 jump to the beginning of the triad kernel
Notice that addition and multiplication are performed as two separate instructions and not as a single fused multiply add (FMA) instruction.
The most frequently used instructions on places two to four (CMP,ADD andJNZ) are used in every kernel to update the running variable j and determine when to exit.
Memory Bandwidth Measurement
My System comprises a CPU AMD 7840U that is connected to dual channel 6400 MT/s DDR5 RAM.
The theoretical max bandwidth is the following:
BW = 2* 64 bit * 6.4 Gbit/s * 1 Byte / 8 bit = 102 GByte/s
Running the STREAM benchmark outputs the following measurements:
jscha@thinkpad:~/dvp/intel-sde$ stream
-------------------------------------------------------------
Function Best Rate MB/s Avg time Min time Max time
Copy: 30165.4 0.005837 0.005304 0.009728
Scale: 26246.2 0.006210 0.006096 0.006791
Add: 30146.8 0.008057 0.007961 0.008529
Triad: 29947.7 0.008326 0.008014 0.009746
-------------------------------------------------------------
Solution Validates: avg error less than 1.000000e-13 on all three arrays
-------------------------------------------------------------
The first observation is that best case practical bandwidth achieved is only 1/3 of the theoretical maximum. The instructions fetched are not counted in the bandwidth measurement. However because they are small enough to fit inside the instruction cache, they are only fetched once from memory and should have almost no impact on the measurement.